品牌型号:联想小新16pro 2021
系统:win11
软件版本:ABBYY FineReader 14
PDF扫描文件的一大缺点就是扫描出来的文件不够清晰,常常将文字扫描得很模糊,既不美观又影响阅读质量,那么针对这些问题又该如何处理呢?接下来小编就讲讲pdf扫描件模糊如何处理清晰,PDF扫描件怎么提取文字的。
一、pdf扫描件模糊如何处理清晰
PDF扫描件模糊一直是困扰大家的一个问题,那么应该如何将模糊界面处理清晰呢?
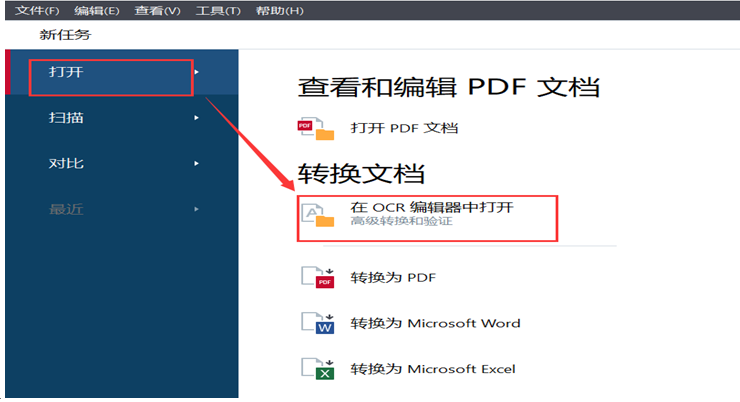
打开ABBYY FineReader 14,在软件的主界面中单击“打开PDF文档”,如下图所示:

图一:打开PDF文档
在跳转出来的页面选择需要处理的扫描文件,并单击“打开”

图二:选择pdf扫描件
在PDF编辑页面,点击上方“工具”,在菜单栏中单击“选项”,即可进入选项页面,在当前页面点击“图像处理”,如下图所示,在“图像预处理设置”下面点击“显示高级设置”,即可将全部设置显示出来。

图三:图像预处理设置
在图像预处理设置页面,可以勾选一些高级设置,如对图像进行歪斜校正、校正图像分辨率等,勾选完成后,点击“确定”,此时就能发现pdf扫描件比原来更清晰了,十分方便。
二、pdf扫描件怎么提取文字
通过上面的学习,相信大家了解了如何处理模糊的pdf扫描件,如果想从扫描件中提取文字又该怎么操作呢?
依旧是在PDF编辑页面,在左上角单击“文件”,然后在出来的菜单栏中依次点击“识别文档”中的“识别文档”如下图所示:

图四:识别文档
单击“识别文档”后,软件就会自动开始识别PDF扫描件的相关内容,几秒钟过后,识别完成,此时就能复制和搜索识别出来的文字,特别方便。
以上就是pdf扫描件模糊如何处理清晰,pdf扫描件怎么提取文字的相关内容了,相信小伙伴们看完后就知道如何处理pdf扫描件了,如果你想学习更多关于pdf扫描件的相关知识,欢迎到ABBYY中文网站上学习。
作者:大饼